


This week, as the Eurovision song contest plans to hold its final rounds, we’re looking at data describing previous entries into the contest. Moreover, we’re doing it through the lens of visualization — and specifically, the use of the Seaborn library to produce our plots.
Seaborn is a wrapper around Matplotlib, the best-known Python plotting library out there. As I mentioned in yesterday’s post, Matplotlib is undoubtedly powerful and flexible. However, its interface is far from intuitive, at least to me, and the results that I produce with it tend to look a bit shabby.
I’ve found that Seaborn gives me the best of all worlds: I have the power of Matplotlib under the hood, but I don’t need to think about making things aesthetically pleasing, because Seaborn has made a lot of good default decisions. Seaborn also encourages me to think about what I’m trying to show with my data, rather than how I’m trying to present it. Once I know what relationships I’m trying to illustrate, Seaborn then gives me a variety of options.
All of this is great — but Seaborn has its own ways of doing things, and they tend to be quite different from the usual Matplotlib ways. That’s why I decided to concentrate on Seaborn this week, to give you some practice working with this amazing package.
Between the music of Eurovision and the visuals of Seaborn, this week was a truly multi-colored issue!
Let’s now dive into the data, as well as answering the questions that I posed.
Data and questions
The data set this week comes from the Eurovision dataset at https://github.com/Spijkervet/eurovision-dataset/blob/master/README.md, created by Janne Spijkervet.
There are two main CSV files of interest in that data set. The one that I asked you to download lists all contestants and entry songs through 2020. You can most easily retrieve it from https://github.com/Spijkervet/eurovision-dataset/releases/download/2020.0/contestants.csv.
Here are the questions I asked you to answer, along with my solutions:
Read the entire contestant CSV file data into a data frame.
For starters, I set up Pandas, along with an import of Seaborn:
import pandas as pd
import seaborn as snsJust as it’s traditional to import pandas with an alias of “pd”, it’s also traditional to import Seaborn with an alias of “sns”. The Seaborn documentation says that this is an internal joke relating to the TV show “The West Wing”; one of the characters there was named Sam Seaborn, and he had monogrammed shirts with the initials SNS on them. I’m not sure how this relates to Python, Pandas, or data analytics, but I’ve always been curious about this, and figured that I might as well share my discovery.
I downloaded the contestants.csv file from GitHub, put it in the same directory as Jupyter, and then ran the following:
filename = 'contestants.csv'
df = pd.read_csv(filename)Notice that I’m just reading the entire CSV file into memory, using all of the defaults of “read_csv”. In other words, we’re assuming:
- the field separator is a comma,
- Pandas will do a good job of guessing the dtype of each column,
- we want all of the columns,
- none of the coulmns should be turned into an index,
- the first line of the file is a header row, naming the columns,
- we don’t want to rename any of the columns from the names in that header row,
- none of the columns should be interpreted as datetime values, and
- the file is small enough that we can read it into memory at once, without chunking it.
Even though it only took 21 ms to load the CSV file into memory, I decided to see how much faster it would be to use the “pyarrow” engine for reading CSV files. Turns out, it took less than 1/3 the time, at only 6 ms. So if you have PyArrow installed (and you can/should, with “pip install pyarrow”), you can save yourself a few milliseconds with the following:
filename = 'contestants.csv'
df = pd.read_csv(filename, engine='pyarrow')The resulting data frame has 1,603 rows and 21 columns. We won’t use all of the columns, and if the data frame were a bit bigger, then perhaps I would think about specifying which ones I want more explicitly. But the total memory used is only 3.3 MB, so I’m not going to waste too much time on it.
Create a line plot showing how many countries participated in Eurovision each year.
In Matplotlib, and also when using the Pandas plotting interface, your first consideration is what kind of plot you want to create.
In Seaborn, the first questions you should be asking are: What kind of data am I working with? And what sort of information am I trying to show about them?
In this case, I asked you to show the number of countries that participated in Eurovision each year. In other words, we want to show the relationship between two numbers: The years (along the x axis) and the total number of participating countries (along the y axis).
When we want to show the relationship between two sets of numbers, Seaborn uses the “relplot”, short for “relational plot.” We use replot for several kinds of plots, including scatter plots (which we’ll get to later), and also for line plots. I hadn’t really thought much about the fact that line plots and scatter plots are basically the same thing, except for the lines, before Seaborn brought this to my attention.
The thing is, our data frame doesn’t have the information that I’ve asked. There is a single row for each entry in each Eurovision contest, and each of those entries has a country name (in the “to_country” column). In order to create our plot, we’ll need to transform that into a data frame in which the years are in one column, and the number of countries are in another column.
This is a perfect job for the “groupby” method, which has three parts:
- The argument to “groupby” is a categorical column. The unique values in this column will be the index in the object returned by our “groupby”. Here, it’ll be the “year” column.
- We then specify which column we want to count inside of square brackets.
- Finally, we specify the aggregation method we want to run. Here, it’ll be “count”, since we want to know how many values there are for each year.
Here’s how our query can look:
df.groupby('year')['to_country'].count()This will return a new series, one with an index (the years) and values (the count per year). We can pass this to “relplot”, specifying that the data should come from our series:
sns.relplot(data=df.groupby('year')['to_country'].count(), kind='line')Notice that we need to tell Seaborn that the data will come from our groupby, by passing the keyword argument “data”. And yes, it’s just fine to pass a series here, and Seaborn will do the right thing, treating the index as the values for its “x” axis and the counts as its values for the “y” axis.
In order to get a line plot, rather than the default scatter plot, we pass “kind=’line’”. There are more specific methods that we could use, but I find it easier to use the overall “relplot” method, in no small part because it also lets me pass more arguments to the underlying Matplotlib library, if I want.
The resulting plot is great, but it’s missing one thing that I had mentioned in my question, namely that I’d like to see the plot on a white background with gray grid lines. In order to get this, we need to set a global Seaborn parameter:
sns.set_style("whitegrid")With this in place, I can make my plot, and I get quite a nice result:
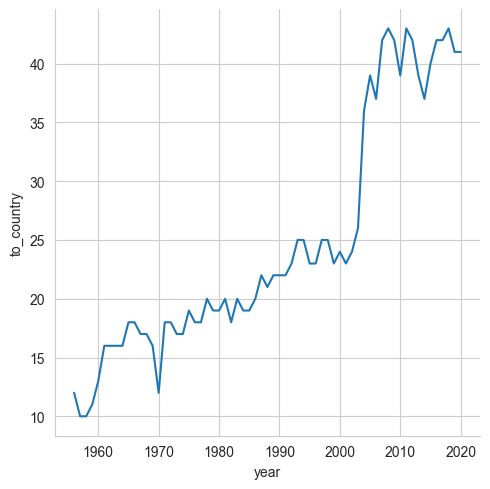
As you can see, the number of participating countries each year grew at a steady pace until the early 2000s, when there was quite a jump.