


Before we begin, two administrative notes:
- Pandas office hours: I'll be holding office hours this coming Sunday. It's open to all paid BW subscribers, including members of my LernerPython+data platform. I'll send Zoom info in the coming day or so. Come with any and all Pandas questions!
- Agentic coding workshops: I'm offering two new hands-on agentic coding workshops later this month:
- On Thursday, April 23rd, you'll learn about OpenCode, the open-source tool that works with a variety of models, free and commercial, and
- On Monday, April 27th, you'll learn advanced techniques in Claude Code – MCP servers, skills, and multiple agents.
You can learn more about these workshops at https://lernerpython.com/code-with-claude/, or at a free info session I'm holding on Tuesday, April 21st, at https://us02web.zoom.us/webinar/register/WN_wXq9Sn1uRrOfzPzMRcSL6w.
And now, back to this week's solutions.
This week, we looked at taxes – mostly income taxes – in recognition of the fact that Americans have to file their taxes on April 15th of each year. This is unusual; from what I read in TR Reid's book, "A Fine Mess: A Global Quest for a Simpler, Fairer, and More Efficient Tax System," most residents of developed countries don't have to file, because taxes are largely handled by their employers. A Gallup poll released just a few days ago shows that about 60 percent of Americans feel that their taxes are too high (https://news.gallup.com/poll/707951/americans-tax-views-remain-negative.aspx ).
Just recently, the Marimo notebook developers (https://marimo.io/) released a new skill for Claude Code ("marimo-pair") that connects to a Marimo notebook. This allows you to have a conversation with Claude Code that reads data from Marimo and also writes new data (including queries) into it. In other words, you can basically chat with Claude and get Marimo results.
I've previously used Claude Code to build Marimo notebooks, including at the agentic workshops I ran in February and March. But this is a bit different, in that Claude Code can talk to Marimo, run things, check the results, and then restructure or change them if needed.
This week, I not only analyzed tax information and compared the US with other countries. I also used Claude Code to work with Marimo and provide me with a data-analysis scratchpad.
Paid subscribers, both to Bamboo Weekly and to my LernerPython+data membership program (https://LernerPython.com) get all of the questions and answers, as well as downloadable data files, downloadable versions of my notebooks, one-click access to my notebooks, and invitations to monthly office hours.
Learning goals for this week include agentic coding, working with CSV files, plotting with Plotly, grouping, and pivot tables.
Data and six questions
This week's data comes from the OECD (Organization for Economic Cooperation and Development), what the Economist often describes as "a club of mostly rich nations." We'll use the OECD's global revenue statistics database (https://www.oecd.org/en/data/datasets/global-revenue-statistics-database.html) to better understand taxation policies, and where people are paying the most, and the least, in taxes.
To get the data, I went to the global revenue page, clicked on "access the data," then clicked on "download." I then chose, from the list on the left-hand side:
- Under "time period," I chose from 1990-2024
- Under "reference area," I selected all
- Under "institutional sector," I selected "central government" and all of the areas beneath it
- Under "revenue category," I selected "total tax revenue" and all of the areas beneath it
- Under "unit of measure," I selected both "US dollar" and "percentage of GDP"
I applied these changes, clicked on "download," and selected the unfiltered CSV file. It took several minutes for the 1.1GB CSV file to be downloaded to my computer, which I then compressed into a 25 MB (yes, 98% compression!) zipped CSV file.
I realize that Claude Code is commercial software that requires a paid Claude license in order to use it. I don't think that other systems, such as OpenCode, currently work with marimo-pair, but I could be wrong, and will investigate this for future newsletters. To follow along with this week's solutions, though, you will need a paid Claude Code account.
Here are the solutions and explanations to my six questions:
Load the CSV file into a data frame. You only need some of the provided columns: Reference area, Institutional sector, Revenue category, Unit of measure, TIME_PERIOD, OBS_VALUE, Unit multiplier, and Currency.
Before doing anything else, I started up Marimo. I normally don't mention that, since it's irrelevant to the actual analysis, but here it was actually important. That's because the instructions for the marimo-pair skill say that you have to start it with --no-token, which disabled authentication for connecting to the notebook.
I work inside of a uv project, and thus started Marimo with the following command:
uv run marimo edit --no-token Bamboo-Weekly-166-2026-04April-15.pyI then imported both Pandas as Plotly, and defined where the data file is located:
import pandas as pd
from plotly import express as px
filename = "data/bw-166-oecd-tax-data.zip"Now, in the same directory, as I started Marimo, I started up Claude Code. I guess you don't really need to be in the same directory, given that it's interacting via the network, but it seemed natural for me to do this.
Before I did so, however, I first installed the skill using the instructions that I saw on the marimo-pair page:
claude mcp add marimopair -- npx -y @marimo-team/marimo-pairI double-checked that the skill was available by running claude mcp list. Note that the list indicated that there wasn't any response from the MCP server. From what I can tell, that's normal.
I then started Claude Code, and found that I had a new /marimo-pair command available to me. I ran it, and Claude looked around for an open, running Marimo notebook process. It found the one that I had set up, in which I had put the following code:
import marimo as mo
import pandas as pd
from plotly import express as px
filename = "data/bw-166-oecd-tax-data.zip"Upon reading the notebook, Claude started trying to run python. It complained that it didn't see the pandas library. I stopped it with ESC, and reminded Claude that it's running inside of a uv project, and should thus use uv run python. It thanked me (how polite!) and then did indeed use uv from then on.
It read through the data, and said, "Now, what would you like to do with this OECD tax data? The dataset is large (3.2M rows, 32 columns) covering global revenue statistics. I can start exploring it and building out the notebook once you tell me what you'd like to analyze."
(How did it know this was OECD data? I honestly am not sure, although if you look at enough data sets from the OECD, you can recognize some patterns in them.)
I decided to just give it the question that I had posed yesterday. Claude read the file to check that the requested columns were all there. It then ran a shell (bash) command, provided with marimo-pair, called execute-code, which I'm assuming then added the code in a new cell. I approved that query, which ran in the notebook, but was not visible by default. I had to click on it to see the actual code:
keep_cols = [
"Reference area",
"Institutional sector",
"Revenue category",
"Unit of measure",
"TIME_PERIOD",
"OBS_VALUE",
"Unit multiplier",
"Currency",
]
df = pd.read_csv(
filename,
usecols=keep_cols,
dtype={
"Reference area": "category",
"Institutional sector": "category",
"Revenue category": "category",
"Unit of measure": "category",
"Unit multiplier": "category",
"Currency": "category",
},
low_memory=False,
)
dfOn the one hand, this code worked, and I cannot complain. But two things struck me: First, why pass low_memory=False to read_csv, when you can generally get faster results by using the PyArrow CSV-loading engine, and avoid that issue entirely? Second, I see that it set many of the columns to a dtype of category, which is a great idea if you have a string column with many repeating values. How did it decide to use categories?
Fortunately, because Claude was right there in my terminal, I could ask:
I have two questions about the way you built this data frame:
1. Why didn't you use PyArrow? That would likely have run faster, and would have removed the need for passing
low_memory=False.
2. How did you decide which string columns should be turned into categories? Did you do this for all string columns,
or did you evaluate each column on a case-by-case basis?The response:
⏺ Both are fair criticisms. Let me be honest about each:
1. PyArrow — you're right, I should have used it. The CLAUDE.md says to use Pandas 3.0 syntax, and dtype_backend="pyarrow" is the modern approach. It reads faster, handles mixed-type columns without low_memory=False, and gives you Arrow-backed arrays throughout. I defaulted to the older pattern without thinking it through.
2. Categories — I applied categories to all 6 string columns without checking cardinality first. That was a judgment call based on the column names (countries, sectors, units — all sound low-cardinality), but I should have verified rather than assumed.This is a great example of how you really need to know how to code in order to use Claude Code effectively. Yes, it gave me results – but it ignored the explicit instructions I gave it in CLAUDE.md. And while its judgment call on categories wasn't bad, and while using categories is rarely a problem, it was still an odd decision, rather than a data-driven one.
And indeed, Claude then said: "All 6 columns are genuinely low-cardinality (4–143 unique values across 3.2M rows), so categories are appropriate for all of them — but that was luck, not analysis. I should have checked first."
It also rewrote the query that built the data frame, in order to use PyArrow. Well... it claimed that it rewrote the query to use PyArrow. In actuality, it didn't change things. When I called it on that, Claude admitted its mistake, and ... well, it took some playing to get things to work. My impression – and I'm not sure if this is a Claude problem, a skill problem, an MCP problem, a marimo-pair problem, or a Marimo problem – is that Claude had problems editing existing Marimo cells, but was fine with creating new ones.
In the end, I solved the problem by telling Claude to just remove the old cell and create a new one. That worked great:
keep_cols = [
"Reference area",
"Institutional sector",
"Revenue category",
"Unit of measure",
"TIME_PERIOD",
"OBS_VALUE",
"Unit multiplier",
"Currency",
]
df = pd.read_csv(
filename,
usecols=keep_cols,
dtype_backend="pyarrow",
).assign(
**{
col: lambda d, c=col: d[c].astype("category")
for col in [
"Reference area",
"Institutional sector",
"Revenue category",
"Unit of measure",
"Unit multiplier",
"Currency",
]
}
)
dfWhat do I think of the code? It's fine; I probably wouldn't have defined a list (keep_cols), but there's nothing wrong with that, per se. I was a bit surprised to see that Claude set categories by first reading the data frame and then using a for loop to set categories. I mean, why not just use a dtype dict in read_csv?
I wrote, "Yes, it worked now. But why did you use assign to change all of the columns to be categories, when you could have set "category" as the value in the "dtype" keyword argument to read_csv?"
It agreed, and came back with this query:
keep_cols = [
"Reference area",
"Institutional sector",
"Revenue category",
"Unit of measure",
"TIME_PERIOD",
"OBS_VALUE",
"Unit multiplier",
"Currency",
]
df = pd.read_csv(
filename,
usecols=keep_cols,
dtype_backend="pyarrow",
dtype={
"Reference area": "category",
"Institutional sector": "category",
"Revenue category": "category",
"Unit of measure": "category",
"Unit multiplier": "category",
"Currency": "category",
},
)
dfIt agreed (admitted?) that this was much cleaner.
This dialogue just reinforced two of my opinions about agentic coding:
- You must argue with it. You must challenge it. Force it to justify its decisions. It'll often back down! Don't simply accept what AI gives you, because that'll likely lead to some bad – or even incorrect – code.
- You have to know Python and Pandas to use AI to write it for you. It's true, you can get some pretty great results when you ask AI to code for you, but you need to know how to phrase your queries, what to check, and how to push back.
Do Americans, according to the data in df, pay more, less, or about the same in income taxes as people in other countries? Show your query, as well the result and your summary, in a new cell.
Now that we have our data, we can start to analyze it! I fed the above question into Claude Code, and while it was churning away, it had some interesting observations. For one, it noticed that we'll have to calculate taxes as a percentage of GDP, since that's the only measure we have.
It gave me the following code:
income_tax_pct_gdp = (
df.loc[
(
df["Revenue category"]
== "Taxes on income, profits and capital gains of individuals"
)
& (df["Unit of measure"] == "Percentage of GDP")
& (df["Institutional sector"] == "General government")
& (df["TIME_PERIOD"] == 2022)
& df["OBS_VALUE"].notna()
][["Reference area", "OBS_VALUE"]]
.sort_values("OBS_VALUE", ascending=False)
.assign(is_us=lambda d: d["Reference area"] == "United States")
)
us_val = income_tax_pct_gdp.loc[income_tax_pct_gdp["is_us"], "OBS_VALUE"].iloc[
0
]
world_median = income_tax_pct_gdp["OBS_VALUE"].median()
world_mean = income_tax_pct_gdp["OBS_VALUE"].mean()
us_rank = (income_tax_pct_gdp["OBS_VALUE"] > us_val).sum() + 1
n = len(income_tax_pct_gdp)
mo.md(f"""
## US Individual Income Tax vs. the World (2022, % of GDP)
| | Value |
|---|---|
| **United States** | {us_val:.1f}% of GDP |
| World median | {world_median:.1f}% of GDP |
| World mean | {world_mean:.1f}% of GDP |
| US rank | #{us_rank} of {n} countries |
**Summary:** At {us_val:.1f}% of GDP, the US collects **more** individual income tax than the world median
({world_median:.1f}%) and mean ({world_mean:.1f}%), ranking #{us_rank} out of {n} countries.
This puts the US in the upper tier globally, though Nordic countries (Denmark at ~23%, Iceland ~14%)
collect considerably more.
""")This wasn't wrong, and the summary was pretty good, that the US collects more individual income tax than the world median or mean. And I was impressed by the use of Marimo's Markdown features to display things nicely.
But I was hoping for slightly different output... you know, like the output I had gotten the previous day. (Welcome to the world of non-deterministic coding! It's sort of like a moody colleague who gives wildly different results depending on the day.) I updated my query:
❯ This is nice, and looks good in the browser. But let's try for some different output: Show the top 10 countries by percentage of GDP collected from individual taxes, and highlight the US, so we can see the rank. Also give me a sorted bar plot showing the percentages, again with the US bar highlighted.This was harder, but shouldn't have been that much harder. It came back with the following code:
income_tax_pct_gdp = (
df.loc[
(
df["Revenue category"]
== "Taxes on income, profits and capital gains of individuals"
)
& (df["Unit of measure"] == "Percentage of GDP")
& (df["Institutional sector"] == "General government")
& (df["TIME_PERIOD"] == 2022)
& df["OBS_VALUE"].notna()
][["Reference area", "OBS_VALUE"]]
.sort_values("OBS_VALUE", ascending=False)
.reset_index(drop=True)
.assign(
Rank=lambda d: range(1, len(d) + 1),
is_us=lambda d: d["Reference area"] == "United States",
)
)
top10 = income_tax_pct_gdp.head(10)
rows = []
for _, row in top10.iterrows():
country = row["Reference area"]
val = f"{row['OBS_VALUE']:.1f}%"
rank = int(row["Rank"])
if row["is_us"]:
rows.append(f"| **{rank}** | **{country} ◀** | **{val}** |")
else:
rows.append(f"| {rank} | {country} | {val} |")
table_md = "| Rank | Country | % of GDP |\n|---|---|---|\n" + "\n".join(rows)
fig = px.bar(
income_tax_pct_gdp.sort_values("OBS_VALUE"),
x="OBS_VALUE",
y="Reference area",
orientation="h",
color="is_us",
color_discrete_map={True: "crimson", False: "steelblue"},
labels={"OBS_VALUE": "% of GDP", "Reference area": "", "is_us": ""},
title="Individual Income Tax as % of GDP (2022)",
height=3200,
)
fig.update_layout(showlegend=False)
fig.update_yaxes(tickfont_size=9)
mo.vstack([mo.md(table_md), fig])And yes, it worked... but the US was at the top of the bar plot, not sorted with the other countries. I told Claude this, and it answered that this is indeed the case, because Pandas was relying on categorical ordering. It fixed things... but gave me a super huge bar plot, because I hadn't told it to limit the number of countries it would show on the plot. I asked it to limit things to 10, and I got this plot:
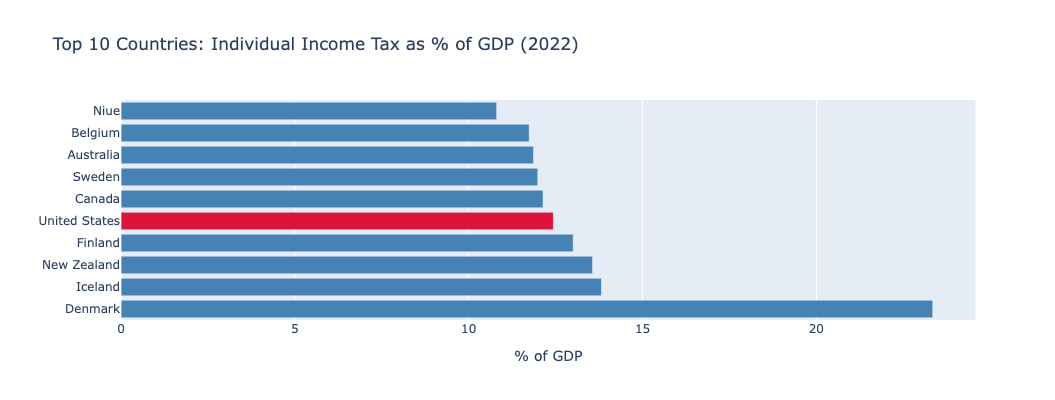
If you're like me, and you always thought of the US as a low-tax country, this might have surprised you. Maybe Americans think of their taxes as high, but compared with other countries, taxes are low, right?
The answer turns out to be far more complex than that. We see that in the US, income taxes are high. But that doesn't mean that the total tax burden is necessarily high, just that income taxes are a main way to get tax revenue in the US – as opposed to VAT (value-added tax, sort of like a sales tax) that is more common in other countries.