


Earlier this month, the Nobel Prizes for 2023 were awarded. This week’s topic is thus the Nobel Prize, its winners, and a variety of ways that we can analyze them. The data itself comes from the Nobel Prize foundation (https://nobelprize.org/ ).
They actually provide two types of data, both via APIs: One describes the prizes, while the other describes the laureates (i.e., the prize winners). Both APIs returned data in JSON format, which you might think would make it easy to import into Pandas. But Pandas expects to have a particular type of JSON, and we didn’t want all of the values in any event — so this week’s tasks turned out to involve both cleaning our data and then joining multiple data frames together.

Data and eight questions
This week, I gave you eight questions and tasks. Let’s go through them:
Retrieve all data about the prizes, from https://api.nobelprize.org/2.1/nobelPrizes. (Note that you'll want to specify the a high limit, to ensure that you get all of the data.) Create a data frame from what you got, with the following columns: awardYear (as an integer), category (English version), dateAwarded (turn into a DateTime), prizeAmount, prizeAmountAdjusted, laureates (it'll be a list of Python dicts), and topMotivation.
Let’s start by loading the basics we’ll need for Pandas:
import pandas as pd
from pandas import Series, DataFrameWith this in place, we can start to retrieve data from the API. In theory, we could use the read_json function to download data from a URL and then import it into a data frame. But there are two problems with this: First, it turns out that the JSON we get back from the Nobel API doesn’t work with read_json. Second, I discovered that read_json cannot read from the API! It would seem that they have some sort of browser-detection mechanism on the Nobel site that only allows particular browsers to retrieve data. (You can check the type of browser via the “user-agent” header that’s passed in an HTTP request. You can also pretend to be another kind of browser by passing a fake value for “user-agent”.)
This means that we’ll need to:
- Retrieve the data via another program or library
- Massage the data to contain the values we want
- Turn the values into a data frame
I decided to use the popular “requests” library for Python, which is a great HTTP client. I used it to retrieve content from the API:
import requests
url = 'https://api.nobelprize.org/2.1/nobelPrizes?limit=100000'
r = requests.get(url)Notice that when retrieving from the API, I pass the “limit” keyword argument, with a value of 100,000 — far higher than the number of prizes given. If I weren’t to include this argument, I would only get information about the first 25 prizes.
The variable r now contains a “response object,” containing the content and all sorts of meta-data in it. Since the content is formatted in JSON, I could use a Python library to turn it into data structures. But why work so hard, when I can have requests do that for me?
prizes_list = r.json()['nobelPrizes']r.json() returns a dictionary with three keys. The data that interests us is a list of dicts under the “nobelPrizes” key. So I retrieved that, and put it into prizes_list.
I could actually get a data frame back by saying
DataFrame(prizes_list)But before I do that, I want to make some changes to the data. That’s partly because several of the values are themselves dictionaries, often because they are translated into several languages. I also want to make some other adjustments to the dictionaries, removing some keys and messing with others.
After some experimentation, I decided that the best way to handle this would be to use a list comprehension, passing in prizes_list and getting out a new list of dicts. The expression used in the comprehension would be a call to a function, prize_info, which would take a single dict and return a new dict based on it — with the modifications in place.
Here’s the function that I ended up writing:
def prize_info(one_entry):
output = one_entry.copy()
for key, value in output.items():
if key == 'awardYear':
output[key] = int(value)
if isinstance(value, dict) and 'en' in value:
output[key] = value['en']
if key.startswith('date'):
output[key] = pd.to_datetime(value)
for one_key in ['links', 'categoryFullName']:
output.pop(one_key)
return outputThis function takes a single dictionary, representing the Nobel Prize given in one category, in one year. I immediately use the dict.copy method to get a new dictionary back. I didn’t really need to do this, but I decided that it would probably be wise to modify a new dict rather than messing with the one we in the original prizes_list data structure.
I then went through every key-value pair in the dict. I turned the “awardYear” value into an integer, ensuring that I could do some math calculations on it later on.
I then looked for any value that was itself a dict, and which had “en” as a sub-key. Such cases showed that the dict contained multiple translations; I replaced the sub-dict with the English translation alone. Notice that it’s usually better to call “isinstance” rather than to run “type” on a data structure.
Finally, I converted any date value from a string into an actual datetime object using the Pandas to_datetime function.
After making these adjustments, I then iterated over several field names I wanted to remove, and used “dict.pop” to do so. You can modify a dict while iterating over it, but you cannot change its size (i.e., the number of key-value pairs). So I had to put the key-removal logic after the modification logic.
The function should be called once for each dict in the list of dicts, prize_list. We can then invoke our comprehension as follows:
new_prizes_list = [prize_info(one_entry)
for one_entry in prizes_list]With our list of dicts in place, we then then create a data frame. Because we can always create a data frame from a list of dicts; the keys will be used as the column names:
prizes_df = DataFrame(new_prizes_list)This is all great, except that now we have a column (“laureates”) that contains Python dicts. We’ll deal with that in question 3.
For now, we have a data frame with all of the Nobel Prizes ever given:
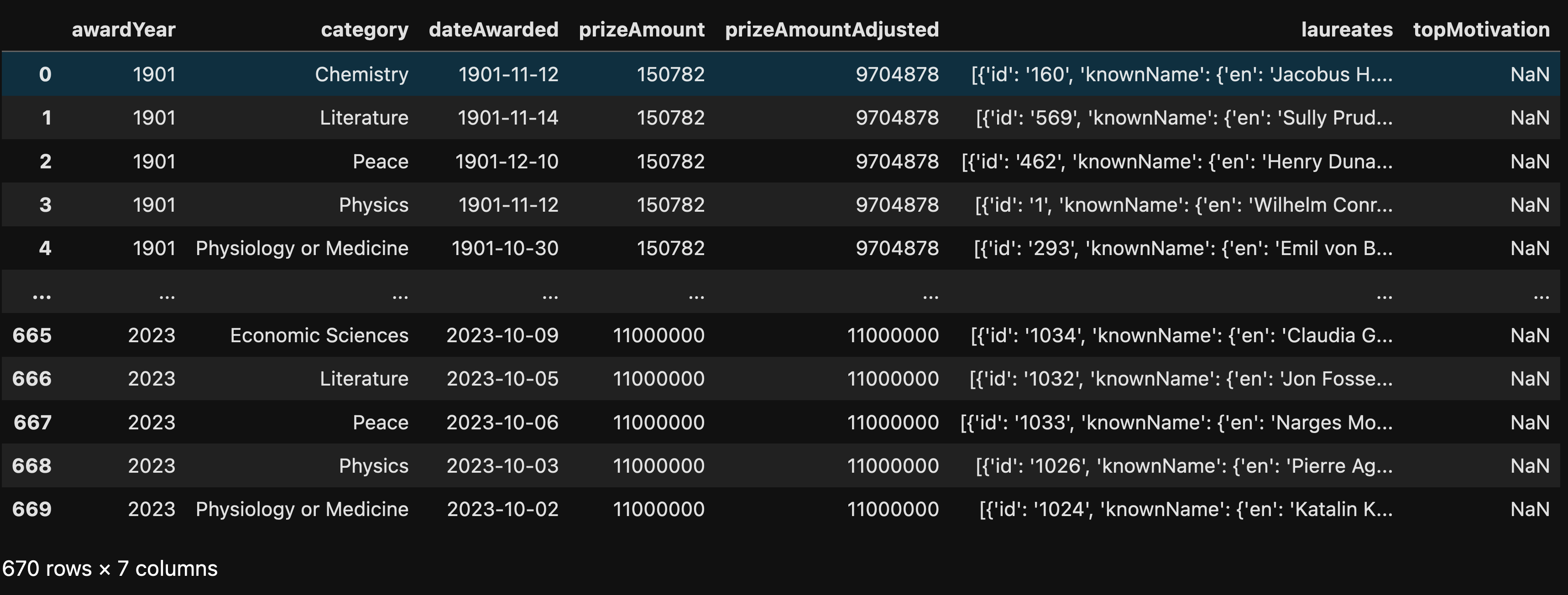
Retrieve all data about the laureates, from https://api.nobelprize.org/2.1/laureates. (Once again, you'll want to specify the a high limit, to ensure that you get all of the data.) Create a data frame from what you got, with the following columns: id, givenName (English), familyName (English), gender (English), birth (only the year), death (only the year), orgName (if available). Make the "id" column the index.
I did something very similar with the laureates data. First, I retrieved it using requests, getting a list of dicts for the laureates:
url = 'https://api.nobelprize.org/2.1/laureates?limit=100000'
r = requests.get(url)
laureates_list = r.json()['laureates']As with the prizes, I passed the “limit” keyword argument, with a value of 100,000, to avoid the 25-element maximum that the API normally returns.
Next, I wrote a function that takes a single dict as input, and returns a modified dict as output:
def laureates_info(one_entry):
output = one_entry.copy()
for key, value in output.items():
if isinstance(value, dict) and 'en' in value:
output[key] = value['en']
if key == 'birth':
output['birth'] = int(value['date'][:4])
if key == 'death':
output['death'] = int(value['date'][:4])
for one_key in ['links', 'wikipedia', 'wikidata',
'sameAs', 'nobelPrizes', 'founded',
'nativeName', 'penName', 'penNameOf',
'foundedCountry', 'foundedCountryNow',
'foundedContinent', 'knownName',
'fullName', 'fileName']:
if one_key in output:
output.pop(one_key)
return outputThe above function is very similar to the prize_info function that we saw earlier.
First, I make a copy of the input dict. Then, I go through each key-value pair, replacing any translation sub-dict with the English version.
Both “birth” and “death” were also keys with complex sub-dicts indicating where and when someone was born. I decided to just replace the values with the year of their birth and death, and turn them into integers. Notice that this works because I’m not changing the number of key-value pairs in the dict, which is OK when iterating over a dictionary. Adding or removing a column wouldn’t have been possible.
I then removed the keys that were uninteresting to me, and returned the output.
The above function works on a single dict, representing a single Nobel laureate. Given that I have a list of those laureates, I can use a list comprehension to run the function on each element of the list, and pass the resulting list of dicts to DataFrame:
new_laureates_list = [laureates_info(one_entry)
for one_entry in laureates_list]
laureates_df = DataFrame(new_laureates_list).set_index('id')Notice that after calling DataFrame on the list of dicts, I get back a data frame. Before returning and assigning it to laureates_df, I invoke “set_index”, ensuring that the “id” column will be the index for the data frame.
Here’s what the data frame looks like on my system:
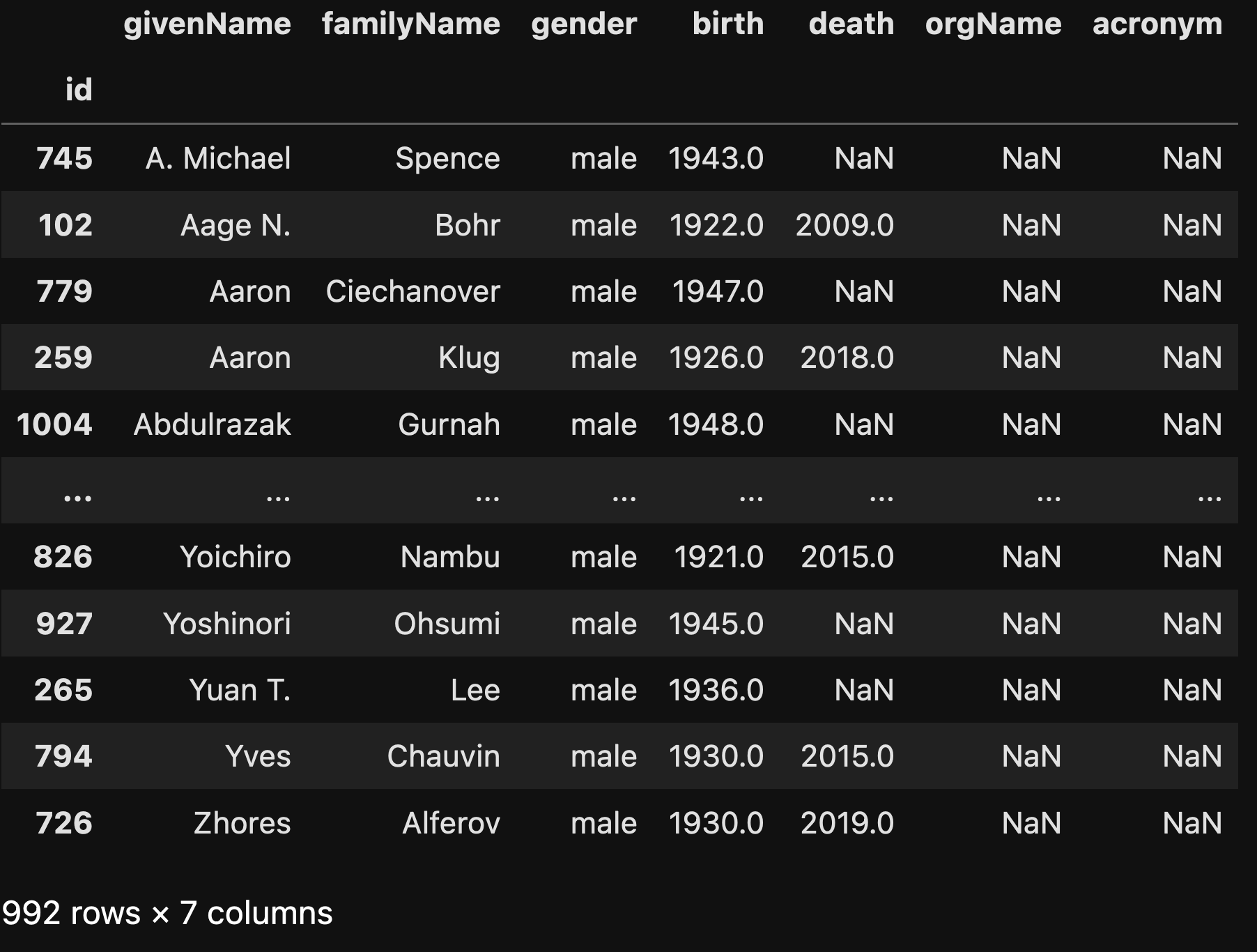
We now have the basic data frames that we’ll need in order to perform some analysis. But before we can do that, we’ll need to do some more manipulation.