


[I'm at Euro Python in Prague this week. If you're attending, then please find me and say "hi"!]
This week, we looked at data from the recent Parliamentary elections in the United Kingdom, one in which Sir Keir Starmer's Labour party swept into victory, ousting the Conservatives after 14 years. One of the many advantages of democracies over other governing systems is that they're more transparent – and in the modern age, this means that they make election data available to the public in digital form. This week, we'll thus look at the official UK election results, seeing what insights we can get.
Data and six questions
This week's data comes from the House of Commons library, part of the UK's Parliament. The full research briefing, including charts and graphs, can be read at
https://commonslibrary.parliament.uk/research-briefings/cbp-10009/
They provide two Excel spreadsheets, one describing the winners of the recent elections, split up per electoral district (known as a "constituency"). A similar, companion document, lists the members who were defeated. You can download them from here:
https://researchbriefings.files.parliament.uk/documents/CBP-10009/Winning-members.xlsx
https://researchbriefings.files.parliament.uk/documents/CBP-10009/Defeated-MPs.xlsx
Below are solutions to the six challenges that I posed yesterday. A link to my Jupyter notebook is, as always, at the end of this post:
Load the two files into a single data frame, with one row for each constituency, and the index being the ons_id columns from each. Columns from the defeated file should have the _defeated suffix attached to their names.
Before doing anything else, I loaded Pandas:
import pandas as pdNext, I defined two variables with the filenames I want to load:
uk_defeated_filename = 'Defeated-MPs.xlsx'
uk_winning_filename = 'Winning-members.xlsx'
Next, I used read_excel to load the first Excel file into a data frame. I passed index_col='ons_id' for that column (as identified in the first row of the Excel file, much like a CSV file) to be our data frame's index:
uk_winning_df = pd.read_excel(uk_winning_filename,
index_col='ons_id')
Next, I loaded the second Excel file into a data frame. However, I kept only a few of the columns, using the usecols keyword argument; the others weren't going to be used in any of our queries, and it annoyed me to have so many unused columns around. I also always forget that the column I mention in index_col must be listed in usecols. Here's the command I ended up using:
uk_defeated_df = (pd
.read_excel(uk_defeated_filename,
index_col='ons_id',
usecols=['ons_id','party_name',
'firstname', 'middlenames',
'surname', 'gender'])
)
I then created a single data frame from the two of these. Because ons_id is the index for both data frames, I can use join to combine them horizontally.
However, column names in Pandas cannot repeat; this is different from the index, where they can. Thus, when we join our two data frames together, we have to resolve the duplicated names by passing rsuffix, which indicates what suffix should be added to the right-hand data frame's column names. (There's also lsuffix, and you can use one or both of them.)
df = uk_winning_df.join(uk_defeated_df, rsuffix='_defeated')
The resulting data frame has 652 rows and 20 columns.
Which party won the greatest number of seats in each region? Which party lost the greatest number of seats in each region?
We know that the Labour party won the overall election. This means that a majority (an overwhelming majority, in fact) of members of Parliament are from Labour. I wanted to know, though, which party won the greatest number of seats — and yes, my original question said "votes," but we don't have that data — in each region. The data divides the UK into regions, and I was curious to know which regions moved from one party to another.
The regions are categorical information, and the party names are, as well. So if your instinct was to use groupby, then that's great – but here, we're grouping by two different categorical columns, which lends itself nicely to a pivot table. I'll invoke pivot_table, telling Pandas to use party names for the rows (index) and region names for the columns. We'll use the count aggregation method, and then it doesn't really matter what column we use for counting, so long as it doesn't have any missing values – so I chose country_name. The query thus looks like this:
(
df
.pivot_table(index='party_name',
columns='region_name',
values='country_name',
aggfunc='count')
.idxmax()
)
Here's a screenshot of what I got:
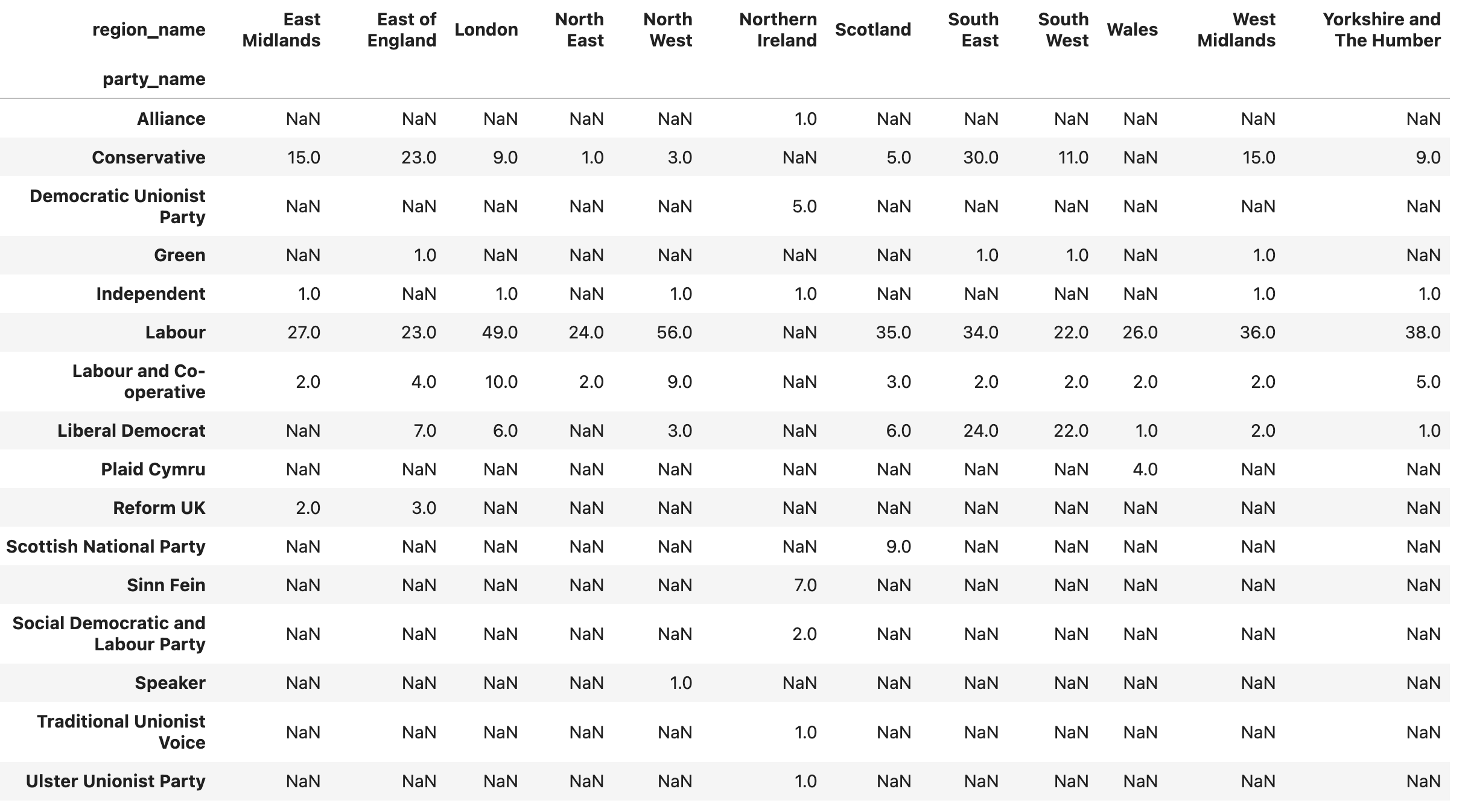
But wait a second: I didn't want to know all of the results for all of the regions. I wanted to know which party won in each region. Fortunately, I can use the idxmax method on the data frame, which will tell me, for each column (i.e. region), the index of the row with the highest value:
(
df
.pivot_table(index='party_name',
columns='region_name',
values='country_name',
aggfunc='count')
.idxmax()
)
The result of this query is:
region_name
East Midlands Labour
East of England Conservative
London Labour
North East Labour
North West Labour
Northern Ireland Sinn Fein
Scotland Labour
South East Labour
South West Labour
Wales Labour
West Midlands Labour
Yorkshire and The Humber Labour
dtype: object
Even without any sort of serious data analysis, we can see that in a a clear majority of regions, the Labour party really did win.
We can perform a similar calculation by using the party_name_defeated category for each constituency:
(
df
.pivot_table(index='party_name_defeated',
columns='region_name',
values='country_name',
aggfunc='count')
.idxmax()
)
The results, as you might expect:
region_name
East Midlands Conservative
East of England Conservative
London Conservative
North East Conservative
North West Conservative
Northern Ireland Democratic Unionist Party
Scotland Scottish National Party
South East Conservative
South West Conservative
Wales Conservative
West Midlands Conservative
Yorkshire and The Humber Conservative
dtype: object