
BW 44: Global economics (solution)
This week, we'll take a look at economic trends among members of the OECD, using Seaborn to create some nice-looking charts.


This week, we looked at economic trends among members of the Organization for Economic Cooperation and Development (OECD), what the Economist likes to call "a club of mostly-rich countries." The idea was to explore three types of data, inflation (via the consumer price index), unemployment, and per-capita GDP.
When considering this sort of data, visualization can help us to better understand the correlations and trends. For that reason, I decided that many of this week’s analyses would be done via plots and charts. It has been several months since we last used the Seaborn package to create our plots, so I thought it would be appropriate to use it, as well.
Hopefully, this week’s questions and tasks gave you not just a better sense of how to use Pandas with real-world data, but also provided you with insights regarding the state of the world economy, of the US economy, and where things seem to be headed over the coming year.

Data and 7 questions
This week’s data came from three different CSV files, all from the OECD’s Web site:
- GDP data for OECD countries, described at https://data.oecd.org/gdp/gross-domestic-product-gdp.htm . The CSV file we'll use is at https://stats.oecd.org/sdmx-json/data/DP_LIVE/.GDP.../OECD?contentType=csv&detail=code&separator=comma&csv-lang=en .
- Unemployment data for OECD countries, described at https://data.oecd.org/unemp/unemployment-rate.htm . The CSV file we'll use is at https://stats.oecd.org/sdmx-json/data/DP_LIVE/.HUR.../OECD?contentType=csv&detail=code&separator=comma&csv-lang=en .
- The consumer price index (CPI) for OECD countries, described at https://data.oecd.org/price/inflation-cpi.htm . The CSV file we'll use is at https://stats.oecd.org/sdmx-json/data/DP_LIVE/.CPI.../OECD?contentType=csv&detail=code&separator=comma&csv-lang=en .
This week, I asked seven questions. While solving the problems, I hope that you gained some experience with Seaborn and the Pandas “pipe” method, along with such topics as pivot tables and joins.
A link to the Jupyter notebook that I used to solve these problems is at the bottom of this edition of the newsletter.
Here are this week’s questions, along with my solutions.
Create a data frame from each of the three CSV files.
Before doing anything else, I made sure that Pandas is available. Since I’m going to be using Seaborn, I also imported it. Note that both of these packages have fairly standard aliases; you don’t have to use them, but given that all of the documentation, examples, and Stack Overflow answers do, I’d strongly suggest it:
import pandas as pd
import seaborn as snsI then created three data frames, all using “read_csv”. This method, like all of the “read_*” methods in Pandas, can take a filename or a URL. The data frames were all relatively small, and I wasn’t sure what columns I would need, so I just slurped all of the data up and created them:
gdp_df = pd.read_csv('https://stats.oecd.org/sdmx-json/data/DP_LIVE/.GDP.../OECD?contentType=csv&detail=code&separator=comma&csv-lang=en')
hur_df = pd.read_csv('https://stats.oecd.org/sdmx-json/data/DP_LIVE/.HUR.../OECD?contentType=csv&detail=code&separator=comma&csv-lang=en')
cpi_df = pd.read_csv('https://stats.oecd.org/sdmx-json/data/DP_LIVE/.CPI.../OECD?contentType=csv&detail=code&separator=comma&csv-lang=en')These three data frames were for GDP, unemployment, and inflation, respectively. They all come in a format that’s common to OECD data sets, with the following columns:
- LOCATION, a three-character country code or a longer code representing a group of countries
- INDICATOR, what we’re measuring. For our three data frames, it’ll be GDP, HUR, and CPI, respectively.
- SUBJECT, the sub-indicators that we’re looking at. For example, CPI can measure total inflation (“TOT”), or it can measure food (“FOOD”), energy (“ENRG”), or total without food and energy (“TOT_FOODENRG”). We’ll only be looking at the total indicators in these problems, but it’s easy to see why you might want to look at sub-indicators for a more nuanced and sophisticated analysis.
- MEASURE, indicating what you’re measuring. For example, the GDP measures both per-capita GDP (“USD_CAP”) and the total GDP, in millions of US dollars (“MLN_USD”).
- FREQUENCY indicates whether we’re looking at annual (“A”), quarterly (“Q”), or monthly (“M”) measurements. These CSV files often include all three measurements, meaning that you need to select the frequency that’s of interest to you.
- TIME is the time for which the measurement was taken. It’s a function of the FREQUENCY column. For a row with “A” (annual) frequency, the TIME value will typically be a four-digit year. But for “Q” (quarterly) frequency, the TIME value will be a four-digit year, followed by “-Q1” for the first quarter, “-Q2” for the second quarter, and so forth. This can be an integer column, but is often an “object” column because it contains strings.
- Value (which is typically not all in ALL CAPS, for reasons I don’t understand) is the actual measurement value. It’s usually a float.
- Finally, the “Flag codes” column indicates whether data is partial, missing, or has other issues that we should know about. I feel comfortable ignoring these doing Bamboo Weekly.
And yes, the capitalization that the OECD uses in its data is inconsistent.
These data frames, as I indicated, aren’t that big:
- gdp_df is 5,288 rows
- hur_df is 70,746 rows
- cpi_df is 294,961 rows
While these might sound large, they really aren’t that big on a modern computer; even cpi_df consumes only 120 MB of memory. That sounded like a lot when I was growing up, but which is fairly small by modern standards.
Use Seaborn to plot total US unemployment over the years. The x axis should contain the final two digits of each year. The y axis should be the percentage of unemployment reported.
In order to create this line plot, I’ll need to have a data frame with at least two columns, for the year and the unemployment number in that year.
I’ll start off by keeping only those rows in which:
- SUBJECT is TOT (because I only want the total unemployment figure)
- LOCATION is USA (because I only want US unemployment)
- FREQUENCY is A (because I want to check annual numbers)
I can do that with “loc”. I perform comparisons, getting a boolean series back from each, and then whittle down the data frame:
(
hur_df
.loc[hur_df['SUBJECT'] == 'TOT']
.loc[hur_df['LOCATION'] == 'USA']
.loc[hur_df['FREQUENCY'] == 'A']
)Note that I could have combined these into a single call to loc, using “&” to combine them. However, it doesn’t change the timing much with a data set this size, and the ease with which I can then eyeball, copy, paste, and modify these queries across the three data frames pushed me to write it this way.
This gives me a pared-down data frame. But it’s not quite enough for our purposes.
First of all, we only want to see the final two digits of each year. I already know that the TIME column will contain four-digit years, because we selected the rows with an annual frequency. I also know that the column’s dtype is “object”, because it contains non-numeric values. I can thus apply the “str.slice” Pandas method to the TIME column, getting new string values back with only the final two characters. (Invoking “str.slice(2)” is similar to saying “[2:]” in a traditional Python slice.
If I invoke str.slice on a column, I get back a new series, one which I can assign to another column. If I want to use method chaining, then I’ll want to use the “assign” method, passing it “TIME” as a keyword argument, so that I’ll replace the existing “TIME” column. In order to create the replacement column, I use an anonymous function via “lambda”, taking a data frame (df_) and applying “str.slice” to the “TIME” column on that data frame.
Why use a lambda here? Why not just invoke str.slice on our original data frame, hur_df? Because we’ve pared down that data frame, and assigning it back to the TIME column won’t work. There are too many rows in hur_df. The whole idea of method chaining is that we slowly but surely transform hur_df, removing and transforming rows and columns until we get what we want.
But wait: Before we can apply our lambda, we should first sort the data frame according to TIME. That’s because pre-lambda, TIME contains four-digit years. Sorting after we’re done will result in some very odd visualizations.
At this point, we now have the following:
(
hur_df
.loc[hur_df['SUBJECT'] == 'TOT']
.loc[hur_df['LOCATION'] == 'USA']
.loc[hur_df['FREQUENCY'] == 'A']
.sort_values('TIME')
.assign(TIME=lambda df_: df_['TIME'].str.slice(2))
)The data frame is now ready for us to hand it to Seaborn and plot the unemployment data. But how can we fit this into our method-chaining paradigm? Normally, I would invoke Seaborn’s “lineplot” method as:
sns.lineplot(data=df, x='TIME', y='Value')But with method chaining, there isn’t any obvious way for me to take the current data frame and pass it as the “data” keyword argument’s value.
That’s where “pipe” comes in. The pipe method is meant for situations in which we want to use method chaining, but we want to use a function along the way. With pipe, we can effectively turn any function into a method. We pass a lambda to pipe, which will get a data frame as its argument. In our case, we’ll then use the data frame we got as an argument to sns.lineplot:
(
hur_df
.loc[hur_df['SUBJECT'] == 'TOT']
.loc[hur_df['LOCATION'] == 'USA']
.loc[hur_df['FREQUENCY'] == 'A']
.sort_values('TIME')
.assign(TIME=lambda df_: df_['TIME'].str.slice(2))
.pipe(lambda df_: sns.lineplot(data=df_, x='TIME', y='Value'))
)The result:
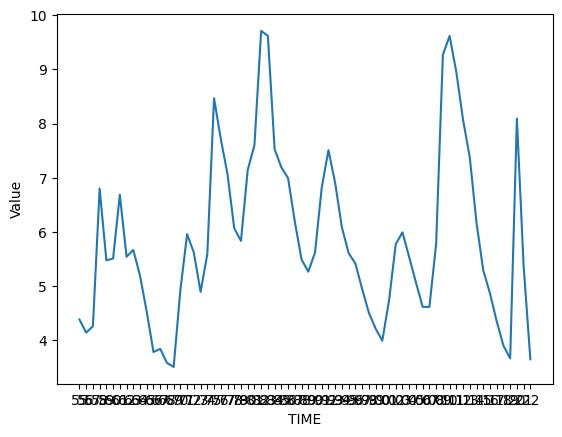
Hmm. That isn’t wrong, but the text is a bit hard to read. I decided to make the image a bit larger, and the font size a bit smaller. There are a few ways to do it, but the easiest is by invoking “sns.set_theme”, a catch-all function that lets us set a variety of display variables in Seaborn:
sns.set_theme(rc={"figure.figsize":(14, 6)})
sns.set_theme(font_scale=0.75)With the above settings in place, my image looked a lot nicer:
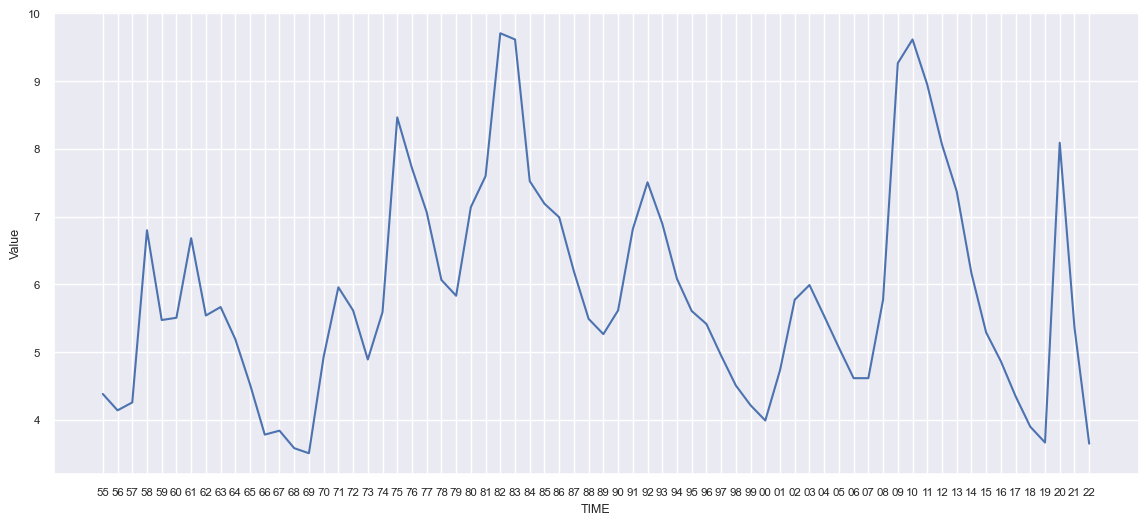
We can see that US unemployment is at a truly historic low point, nearly matched in the pre-pandemic boom, and bested more than 50 years ago.
No wonder economists have been saying that the US economy is doing quite well; if you want a job, you can probably find one, and you can ask for a good wage, given the tight labor market.

